

امروز : شنبه, ۹ تیر , ۱۴۰۳
پایداری | متن کامل رایگان | بهینه سازی عملکرد باتری لیتیوم یون: ادغام یادگیری ماشین و هوش مصنوعی قابل توضیح برای مدیریت انرژی پیشرفته
۱٫ معرفی باتریهای لیتیوم یون (LiBs) منابع انرژی حیاتی برای وسایل نقلیه الکتریکی (EVs) هستند که مزایایی مانند چگالی انرژی بالا، سبک وزن، نرخهای خود تخلیه پایین، قابلیتهای شارژ سریع و حداقل نیازهای تعمیر و نگهداری را ارائه میدهند. این ویژگی ها LiB ها را به عنوان گزینه برق ترجیحی برای خودروهای برقی در کاربردهای […]

۱٫ معرفی
اجرای تکنیکهای هوش مصنوعی قابل توضیح (XAI) در باتریهای لیتیوم یونی بسیار مهم است زیرا شفافیت و قابلیت تفسیر مدلهای پیشبینی را افزایش میدهد و امکان درک و مدیریت بهتر عملکرد و سلامت باتری را فراهم میکند. تازگی اصلی این کار، ادغام تکنیکهای XAI به عنوان جایگزینی برای روشهای سنتی مورد استفاده در ارزیابی SoH LiBs است. سیستم های مدیریت باتری فعلی هنوز برای تشخیص فرآیندهای تخریب و پیری که عملکرد باتری را به سرعت تحت تأثیر قرار می دهند، کافی نیستند. رویکرد مبتنی بر XAI پیشنهادی، مدلهای یادگیری ماشین و هوش مصنوعی را توصیف میکند که مانند یک جعبه بسته برای پیشبینی دقیقتر شاخصهای سلامت باتری کار میکنند. بنابراین، ویژگیهای مؤثر بر مدلها پتانسیل افزایش طول عمر و به حداقل رساندن هزینههای نگهداری را دارند. علاوه بر این، هدف این روش کاهش اثرات زیست محیطی و پایدارتر کردن استفاده از منابع با بهینه سازی زمان تعویض باتری است. بنابراین، در محدوده مطالعه، یک نوآوری استراتژیک از نظر پایداری و قابلیت اطمینان در زمینه فناوری های باتری، به ویژه با استفاده از XAI ارائه شده است.
۲٫ مواد و روشها
۲٫۱٫ تعریف مجموعه داده
۲٫۲٫ انتخاب مدل
این مطالعه الگوریتم های یادگیری ماشینی مانند AdaBoost، تقویت گرادیان، XGBoost، LightGBM و CatBoost را برای آموزش مدل ارزیابی و مقایسه کرد. انتخاب این الگوریتم ها بر اساس ویژگی ها و مزایای منحصر به فرد آنها بود. هر الگوریتم بسته به ویژگی های مجموعه داده و نتایج مورد نظر، نقاط قوت و ضعف خود را دارد. مقایسه و ارزیابی این الگوریتم ها برای تعیین مناسب ترین الگوریتم برای یک مجموعه داده خاص ضروری است. متدهای Ensemble مانند AdaBoost، gradient boosting، XGBoost، LightGBM و CatBoost از جمله این الگوریتم ها بودند. هر الگوریتم تحت آموزش زیرمجموعه آموزشی مجموعه داده قرار گرفت و سپس برای عملکرد در زیر مجموعه آزمایشی مورد ارزیابی قرار گرفت. علاوه بر این، یک نمای کلی از SHAP، یکی از روشهای XAI، برای ارائه و تفسیر دادههای نتایج و مدل LightGBM معرفی شد.
۳٫ نتایج تجربی
ارزیابیهای عملکرد الگوریتمهای بررسیشده، تحلیلهای مقایسهای و موفقیت پیشبینی هر مدل بر روی SoH از LiBs در این بخش در زیر بخشهای مختلف توسعه و مورد بحث قرار گرفتهاند. علاوه بر این، اثرات روش SHAP بر درک پیشبینیهای مدل و تعیین تصمیمها سپس ارزیابی میشوند.
۳٫۱٫ معیارهای ارزیابی مدل
۳٫۲٫ آموزش مدل
۳٫۳٫ نتایج مقایسه مدل
LightGBM یک الگوریتم تقویتی است که برای عملکرد و کارایی بهینه شده است. رویکردهای نوآورانه ای مانند یادگیری مبتنی بر هیستوگرام و رشد درخت مبتنی بر برگ، آن را قادر می سازد تا به سرعت و به طور موثر بر روی مجموعه داده های بزرگ و با ابعاد بالا کار کند. این ویژگی ها LightGBM را به یک الگوریتم انتخابی، به ویژه در پروژه های یادگیری ماشینی در مقیاس بزرگ تبدیل می کند. در حالی که رشد درخت در سایر الگوریتمهای تقویتکننده (به عنوان مثال XGBoost) به صورت سطحی اتفاق میافتد، رشد برگ در LightGBM استفاده میشود. رشد برحسب برگ درختان را عمیق تر می کند و از برگ با بالاترین میزان خطا شروع می شود. به این ترتیب، مرزهای تصمیم گیری پیچیده تر با ظرفیت تعمیم بهتر در مقایسه با درختان با عمق یکسان ایجاد می شود.
۳٫۴٫ نتایج مدل یادگیری گروه
به عنوان بخشی از این مطالعه، یک مدل رگرسیون مبتنی بر رأی به نام VotingRegressor توسعه داده شد. VotingRegressor پیشبینیهای مدلهای رگرسیون مختلف را برای ایجاد یک مدل مجموعه ترکیب میکند. در این تنظیمات، مدل شامل پیشبینیکنندههایی از پنج الگوریتم رگرسیون است: تقویت گرادیان، XGBoost، AdaBoost، LightGBM و CatBoost.
علیرغم اینکه مدل گروهی نتایج خوبی به همراه داشت، مدل LightGBM عملکرد بهتری را در مقایسه با مدل گروهی نشان داد. از جمله دلایل این امر، توانایی LightGBM برای تطبیق بهخوبی با ویژگیهای مجموعه داده و اثربخشی آن در مدیریت کارآمدتر پیچیدگیها در مجموعه داده با روش رشد مبتنی بر برگ است. از سوی دیگر، در مدل مجموعه، ترکیب پیشبینیهای مدلهای مختلف با میانگین ساده ممکن است همیشه به اندازه کافی ویژگیها و نقاط قوت مدلهای فردی را منعکس نکند. با در نظر گرفتن این عوامل، عملکرد برتر LightGBM در مقایسه با سایر مدل ها، اهمیت پیش پردازش مناسب داده ها و پارامترسازی مدل را برجسته می کند.
۳٫۵٫ تجزیه و تحلیل توضیح پذیری مدل های هوش مصنوعی
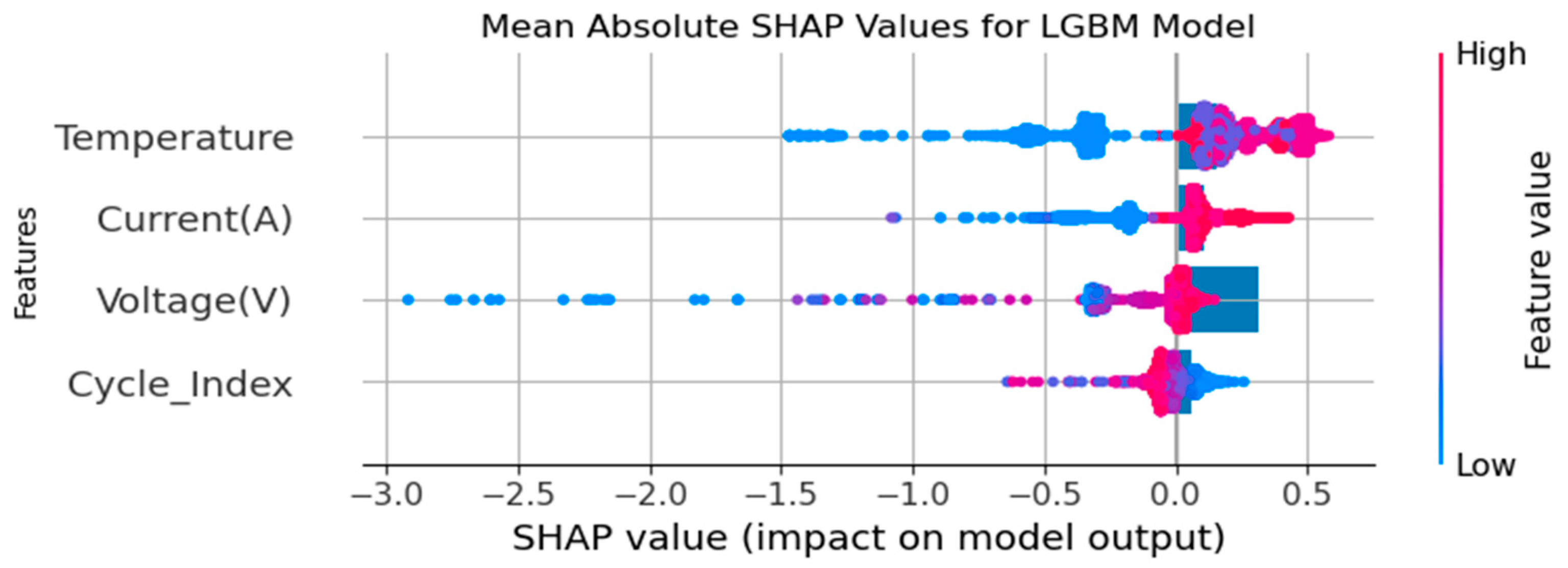
چرخه_شاخص اهمیت تأثیر شاخص چرخه بر پیش بینی ها را نشان می دهد. شاخص چرخه به عنوان یک مهر زمانی موقت در طول یک چرخه عمل می کند. به طور کلی، تعداد دفعات تکرار یک چرخه یا مدت زمان سپری شده در طول یک چرخه را نشان می دهد. یک مقدار SHAP بالا نشان می دهد که شاخص چرخه نقش مهمی در پیش بینی ها ایفا می کند.
درجه حرارت اغلب ممکن است یک عامل مهم در یک مدل یادگیری ماشین در چندین برنامه باشد. به عنوان مثال، دما نقش حیاتی در بازده انرژی، سرعت واکنش شیمیایی و بسیاری از فرآیندهای فیزیکی دیگر دارد. یک مقدار SHAP بالا نشان می دهد که دما به طور قابل توجهی بر پیش بینی تأثیر می گذارد.
ولتاژ (V) نشان دهنده سطح انرژی در یک سیستم الکتریکی است. ولتاژ یک عامل اساسی است که بر بازده انرژی و عملکرد سیستم تأثیر می گذارد. یک مقدار SHAP بالا نشان می دهد که ولتاژ برای پیش بینی ها ضروری است.
جریان (A) جریان انرژی را در یک واحد الکتریکی نشان می دهد. ارتفاع جریان نشان می دهد که یک مدار چقدر انرژی مصرف یا تولید می کند. یک مقدار SHAP بالا نشان می دهد که جریان به طور قابل توجهی بر پیش بینی ها تأثیر می گذارد. تفسیر این مقادیر برای درک اینکه کدام ویژگی های مدل در پیش بینی ها بیشترین اهمیت را دارند ضروری است. به عنوان مثال، ویژگیهایی با مقادیر SHAP بالا ممکن است در پیشبینیهای مدل وزن بیشتری به خود اختصاص دهند، در حالی که ویژگیهایی با مقادیر پایین ممکن است تأثیر کمتری داشته باشند. این اطلاعات ممکن است برای تعیین اینکه چه ویژگی هایی باید برای بهبود عملکرد مدل کار شود، استفاده شود.
۴٫ بحث
تحقیقات اخیر پیشرفت قابل توجهی در پیش بینی مدیریت عملکرد LiB در EV با استفاده از تکنیک های ML داشته است.
-
پو [۳۳] یک بررسی جامع از روشهای ML برای تخمین حالت در کاربردهای EV ارائه کرد، و پتانسیل این تکنیکها را در پرداختن به چالشهای ویژگیهای باتری متغیر با زمان و غیرخطی برجسته کرد.
-
لعنتی [۳۴] این زمینه را با ارائه روشی برای شبیهسازی عملکرد بستههای LiB در خودروهای الکتریکی، دستیابی به دقت بالا در پیشبینی ولتاژ و تخمین دمای بسته باتری، بیشتر کرد. این مطالعات در مجموع بر نقش امیدوارکننده ML در افزایش مدیریت عملکرد LiBs در خودروهای الکتریکی تاکید میکنند. در نظرسنجی، تقویت به صورت تکراری کار کرد و در هر تکرار یک مدل جدید اضافه کرد. آخرین مدل سعی در اصلاح اشتباهات مدل قبلی دارد. این فرآیند با گام برداشتن در امتداد گرادیان تابع ضرر انجام می شود. این برای یک برنامه خاص مانند گرادیان های تقویتی نیز صادق است، اما، به طور کلی، تکنیک تقویت شامل اصطلاحات منظم سازی که پیچیدگی مدل را کنترل می کند، نیست و به طور کلی با هدف کاهش خطاهای مدل است.
در مطالعات:
-
این روش شامل انجام آزمایشهای تخلیه WLTP بر روی یک سلول NMC و استفاده از دادههای تاریخی برای ساخت مدلهای درختی تقویتشده برای پیشبینی ولتاژ بود. اندازهگیریهای آزمایشهای تخلیه WLTP در دماهای مختلف روی یک سلول NMC، همراه با ولتاژ پایانه، نرخ تخلیه و دما در چهار نقطه انجام شد. [۳۲]، و پیش بینی ولتاژ سلول به عنوان توالی نتیجه در آینده (پیش بینی SoC باتری). این مطالعه آزمایشهای تخلیه WLTP را روی یک سلول NMC انجام داد و نشان داد که یک استراتژی پیشبینی مستقیم چند مرحلهای با تکنیکهای یادگیری ماشین استاندارد در پیشبینی SoC باتری کارآمد و قابل استفاده است.
-
این روش شامل پیشنهاد یک مدل فرآیند گاوسی پیچیده (MCGP) چند خروجی برای تخمین ظرفیت سلولهای LiB در خودروهای الکتریکی و اعتبارسنجی آن با دادههای تجربی از سلولهای باتری خاص بود. تخمین ظرفیت سلولهای LiB، دقت تخمین SoC، و عمر مفید باقیمانده سلول باتری (RUL) در [۳۵]. این مطالعه یک مدل فرآیند گاوسی پیچیده (MCGP) چند خروجی را برای تخمین دقیق ظرفیت سلولهای LiB در خودروهای الکتریکی معرفی کرد. مدل پیشنهادی میتواند دقت تخمین SoC را بهبود بخشد و به عنوان یک ابزار دقیق برای پیشبینی RUL سلول باتری عمل کند.
-
یک استراتژی مدیریت انرژی پیشبینیکننده پیری باتری و دما برای خودروهای هیبریدی موازی برای مدلسازی کنترل پیشبینیکننده (MPC) و بهینهسازی با اصل حداقلسازی Pontryagin (PMP) استفاده شد. [۳۶]. اینها استراتژیهای مدیریت انرژی پیشبینیکننده کهنهشدن باتری و دما برای خودروهای هیبریدی موازی هستند. این مطالعه یک استراتژی مدیریت انرژی پیشبینیکننده پیری باتری و آگاهی از دما را با روش PMP برتر از برنامهنویسی پویا ایجاد کرد و نشان داد که یک استراتژی آگاه از دمای باتری میتواند مصرف کل انرژی را کاهش دهد.
-
تکنیکهای هوش مصنوعی برای تخمین SoC باتری، با استفاده از مجموعه دادههای Panasonic 18650PF، انجام پیش پردازش و استخراج ویژگی، و ارزیابی عملکرد مدل با معیارهای مختلف در [۳۱]. شرکتکنندگان هیچ مداخلهای دریافت نکردند زیرا این مطالعه بر روی کاربرد تکنیکهای هوش مصنوعی برای تخمین وضعیت شارژ باتری (SoC) در LiBs متمرکز بود.
-
تخمین وضعیت شارژ باتری (SoC) با استفاده از تکنیکهای هوش مصنوعی تمرکزی برای عملکرد مدل ANN است (R2 ارزش ۰٫۹۹۲۵). مدل ANN از سایر تکنیکهای هوش مصنوعی در تخمین وضعیت شارژ باتری (SoC) با R بالا بهتر عمل کرد.۲ ارزش ۰٫۹۹۲۵، نشان دهنده توانایی آن در گرفتن الگوهای اساسی برای برآوردهای دقیق است.
بسیاری از مطالعات بر بهبود دقت پیشبینی ظرفیتهای LiB متمرکز شدهاند. با این حال، نمونه هایی از استفاده از روش های XAI در این زمینه به ندرت مشاهده می شود. بنابراین، مطالعه فعلی انجام شده با استفاده از SHAP به طور قابل توجهی به ادبیات کمک می کند. مقادیر SHAP برای درک اینکه کدام ویژگی و تا چه حد بر پیشبینی مدل تأثیر میگذارد استفاده میشود. به ویژه، متغیرهای مؤثر بر عملکرد باتریهای لیتیوم یون و سهم آنها در پیشبینیها به تفصیل تجزیه و تحلیل شدهاند. مطالعه حاضر درک بهتری از مدلهای مورد استفاده برای پیشبینی وضعیت و ظرفیت LiBs را امکانپذیر کرد و در نتیجه قابلیت اطمینان این پیشبینیها را افزایش داد.
یافتههای مورد بحث در فصل نتایج تجربی ما با روشهای یادگیری ماشین موجود مورد استفاده در پیشبینی وضعیت و ظرفیت LiBs مقایسه میشوند. این مطالعه سهم قابل توجهی در ارائه بینش های استراتژیک برای بهینه سازی و توسعه سیستم های مدیریت باتری، به ویژه از طریق استفاده از روش های XAI مبتنی بر SHAP دارد. یافتههای ما نشان میدهد که مقادیر SHAP نقش مهمی در درک اینکه کدام ویژگیها بر پیشبینیهای مدل تأثیر میگذارند و تا چه اندازه ایفا میکنند. این رویکرد کاربردهای خود را با تعمیق بخشیدن به مجموعه دانش در فنآوریهای باتری گسترش میدهد. به طور خاص، توانایی مدلهای ANN و GPR برای پیشبینی SoC با دقت بالاتر نسبت به سایر الگوریتمهای یادگیری ماشین، ظرفیت این تکنیکها را برای ثبت رفتار باتری برجسته میکند. در نتیجه، این مطالعه قابلیت اطمینان مدلهای مورد استفاده برای پیشبینی عملکرد LiBs را بهبود میبخشد و توسعه سیستمهای مدیریتی را قادر میسازد که استفاده از باتری را کارآمدتر کند.
علاوه بر این، از طریق این رویکرد، اطلاعات استراتژیک ممکن است برای بهینهسازی و توسعه سیستمهای مدیریت باتری ارائه شود که امکان استفاده کارآمدتر از باتری را فراهم میکند. بنابراین، مطالعه XAI مبتنی بر SHAP دانش فنآوریهای باتری را عمیقتر میکند و کاربردهای آنها را گسترش میدهد.
۵٫ نتیجه گیری و روندهای آینده
این مطالعه به طور خاص عملکرد مدلهای مختلف یادگیری ماشین را در پیشبینی ظرفیت تخلیه LiBs با تمرکز بر AdaBoost، تقویت گرادیان، XGBoost، LightGBM، CatBoost و یک مدل یادگیری گروهی ارزیابی کرد. یافتهها نشان داد که LightGBM از مدلهای دیگر با کمترین مقادیر MAE و MSE و بالاترین مقدار مربع R عملکرد بهتری داشت، که نشاندهنده همبستگی قوی بین مقادیر پیشبینیشده و واقعی است. هر دو افزایش گرادیان و XGBoost سطوح عملکرد مشابهی را نشان دادند اما کمی از LightGBM عقب ماندند.
مدل یادگیری گروهی عملکرد رقابتی را با تأکید بر اثربخشی ترکیب چند مدل برای به دست آوردن یک چارچوب پیشبینی قوی به نمایش گذاشت. استفاده از مقادیر SHAP برای توضیح موفقترین مدل، LightGBM، اهمیت ویژگیهای مختلف مانند دما، شاخص سیکل، ولتاژ و جریان را در پیشبینیهای تأثیرگذار برجسته کرد. به ویژه، دما به عنوان یک عامل تعیین کننده مهم ظاهر شد. تجزیه و تحلیلهای XAI نشان داد که دمای بالا بر ظرفیت تخلیه تأثیر منفی میگذارد و با انتظارات فیزیکی در مورد عملکرد باتری همسو میشود.
نتایج این مطالعه نشان میدهد که مدلهای یادگیری ماشین از نظر تئوری برای پیشبینی شرایط و ظرفیت LiBs مؤثر هستند. با این حال، کاربرد این مدلها در سناریوهای دنیای واقعی شامل چالشهای عملی فراتر از کفایت الگوریتم، مانند پیچیدگی مدل، الزامات محاسباتی، و ظرفیت پردازش دادههای بلادرنگ است که ممکن است ادغام مدل را در برنامههای صنعتی محدود کند. در سیستمهای مدیریت باتری برای وسایل نقلیه الکتریکی، مدلهای یادگیری ماشینی میتوانند با تغذیه دادههای بلادرنگ مانند شرایط ترافیک، سبک رانندگی و آب و هوا، عمر باتری را بهینه کرده و برد را به حداکثر برسانند. در شبکههای هوشمندی که انرژیهای تجدیدپذیر را در خود جای دادهاند، این مدلها تقاضای انرژی، بهبود بهرهوری انرژی و کاهش هزینههای عملیاتی را پیشبینی میکنند. در کارخانهها، مدلهای یادگیری ماشینی میتوانند با تعیین برنامههای تعمیر و نگهداری تجهیزات با باتری، خرابیها را پیشبینی کنند. چنین کاربردهای بلادرنگ ارزش عملی مدل و ادغام موثر آن در برنامه های صنعتی را نشان می دهد. پیادهسازی الگوریتمهای پیچیدهتر BMS که شامل یادگیری ماشینی و هوش مصنوعی است، سلامت باتری را بهتر نظارت و مدیریت میکند و از چرخههای شارژ و دشارژ بهینه برای افزایش عمر باتری اطمینان میدهد.
مطالعات آینده ممکن است روشهای مجموعه پیچیدهتری را با ادغام مدلهای یادگیری ماشینی جدیدتر یا متنوعتر برای افزایش دقت پیشبینی بررسی کنند. ادغام این مدلها در سیستمهای مانیتورینگ بلادرنگ برای وسایل نقلیه الکتریکی میتواند پیشبینیهای پویا قابل انطباق با شرایط متغیر را ارائه دهد، بنابراین مصرف باتری را بهینه کرده و عمر باتری را افزایش میدهد. تجزیه و تحلیل عمیق تر در مورد ویژگی های اضافی که ممکن است بر عملکرد باتری تأثیر بگذارد، مانند عوامل محیطی یا تخریب مواد، بینش جامع تری ارائه می دهد. گسترش مدلهای مبتنی بر پیشبینی به سایر فناوریهای باتری و ذخیرهسازی میتواند کاربرد و تأثیر آنها را در سیستمهای مختلف انرژی گسترش دهد.
تمرکز مداوم بر مدلهای XAI، بهویژه در کاربردهای حساس مانند وسایل نقلیه الکتریکی که درک پیشبینیهای مدل ممکن است بهطور قابلتوجهی بر تصمیمگیریهای طراحی و عملیاتی تأثیر بگذارد، بسیار مهم خواهد بود. همانطور که مدلهای یادگیری ماشین در کاربردهای حیاتی رایجتر میشوند، توسعه استانداردها و چارچوبهای نظارتی برای اطمینان از قابلیت اطمینان و امنیت آنها ضروری میشود. گنجاندن XAI نه تنها شفافیت را تضمین می کند، بلکه بینش عملی را نیز ارائه می دهد که می تواند آینده توسعه فناوری باتری را شکل دهد. همانطور که تقاضا برای راه حل های انرژی پایدار همچنان در حال افزایش است، توسعه مدل های پیش بینی قوی تر و توضیح آنها با روش های XAI در روشن کردن خواص فیزیکی LiBs و رابطه بین الگوریتم های پیش بینی بسیار مهم خواهد بود.
هنگامی که باتری های لیتیوم یونی به دلیل کاهش عملکرد به پایان عمر خود می رسند، ضروری است که به طور مسئولانه به دفع و بازیافت آنها رسیدگی شود. علاوه بر این، نوسازی باتریهای مصرفشده برای استفاده ثانویه در کاربردهای کمتر میتواند چرخه عمر آنها را افزایش داده و به اقتصاد چرخشی کمک کند. توسعه فرآیندهای کارآمد و پایدار برای استفاده از باتریهای لیتیوم یون پایان عمر برای به حداقل رساندن اثرات زیستمحیطی و حمایت از تقاضای فزاینده برای مواد باتری به شیوهای سازگار با محیط زیست بسیار مهم است.
مشارکت های نویسنده
روش، SO و AA. نرم افزار، SO و BE. اعتبارسنجی، BE; تحقیق، EB; منابع، AA; نوشتن-پیش نویس اصلی، BE; نوشتن-بررسی و ویرایش، Ş.S. و EB؛ Supervision, SO, Ş.S. و EB؛ مدیریت پروژه، SO; تامین مالی، Ş.S. و AA همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این مقاله توسط برنامه تحقیقاتی و نوآوری Horizon Europe اتحادیه اروپا تحت «نسل بعدی سیستم باتریهای حالت جامد چند منظوره، مدولار و مقیاسپذیر» (توسعهیافته)، موافقتنامه گرانت شماره ۱۰۱۱۰۲۲۷۸ پشتیبانی شد.
بیانیه هیئت بررسی نهادی
قابل اجرا نیست.
بیانیه رضایت آگاهانه
قابل اجرا نیست.
بیانیه در دسترس بودن داده ها
مشارکت های اصلی ارائه شده در مطالعه در مقاله گنجانده شده است، سوالات بیشتر را می توان به نویسنده مربوطه هدایت کرد.
قدردانی ها
این تحقیق با همکاری تیم MOBILERS در دانشگاه سیواس جمهوریت و گروه تحقیقات باتری در دانشگاه علم و فناوری سیواس (SBTU) انجام شد.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- اویوکو، اس. دوگان، اف. آکسوز، ا. Biçer, E. تجزیه و تحلیل مقایسه ای روش های یادگیری ماشینی که معمولاً برای پیش بینی و مدیریت عملکرد باتری لیتیوم یونی در وسایل نقلیه الکتریکی استفاده می شود. Appl. علمی ۲۰۲۴، ۱۴، ۲۳۰۶٫ [Google Scholar] [CrossRef]
- اویوکو، اس. دومن، اس. دورو، İ. آکسوز، ا. Biçer، E. تخمین ظرفیت تخلیه برای باتری های لیتیوم یون: یک مطالعه مقایسه ای. تقارن ۲۰۲۴، ۱۶، ۴۳۶٫ [Google Scholar] [CrossRef]
- کلاس، وی. بهم، م. لیندبرگ، جی. ثبت دینامیک باتری لیتیوم یون با مدل باتری مبتنی بر ماشین بردار پشتیبانی. J. منابع قدرت ۲۰۱۵، ۲۹۸، ۹۲-۱۰۱٫ [Google Scholar] [CrossRef]
- لاادجل، ک. کاردوسو، برآورد AJM وضعیت باتریهای لیتیوم یونی در کاربردهای خودروهای الکتریکی: مسائل و وضعیت هنر. الکترونیک ۲۰۲۱، ۱۰، ۱۵۸۸٫ [Google Scholar] [CrossRef]
- لی، ی. لو، ال. ژانگ، سی. لیو، اچ. ارزیابی وضعیت سلامت برای باتریهای لیتیوم یونی با استفاده از تحلیل انرژی افزایشی و حافظه کوتاهمدت دو جهته. ورلد الکتر. وه جی. ۲۰۲۳، ۱۴، ۱۸۸٫ [Google Scholar] [CrossRef]
- Sarmah, SB; کالیتا، پ. گارگ، ا. نیو، X.-D. ژانگ، X.-W. پنگ، ایکس. Bhattacharjee, D. مروری بر برآورد وضعیت سلامت سیستمهای ذخیرهسازی انرژی: چالشها و راهحلهای ممکن برای کاربردهای آیندهنگر بستههای باتری لیتیوم یونی در وسایل نقلیه الکتریکی. J. الکتروشیمی. مبدل انرژی ذخیره سازی ۲۰۱۹، ۱۶۰۴۰۸۰۱٫ [Google Scholar] [CrossRef]
- هارپر، جی دی جی؛ کندریک، ای. اندرسون، PA; مروزیک، دبلیو. کریستنسن، پی. لامبرت، اس. گرین وود، دی. Das، PK؛ احمد، م. میلوویچ، ز. و همکاران نقشه راه برای اقتصاد دایره ای پایدار در فناوری های لیتیوم یون و باتری های آینده. J. Phys. انرژی ۲۰۲۳، ۵۰۲۱۵۰۱٫ [Google Scholar] [CrossRef]
- لو، ال. هان، ایکس. لی، جی. هوآ، جی. اویانگ، ام. مروری بر مسائل کلیدی برای مدیریت باتری لیتیوم یونی در خودروهای الکتریکی. J. منابع قدرت ۲۰۱۳، ۲۲۶، ۲۷۲-۲۸۸٫ [Google Scholar] [CrossRef]
- مدنی، س.س. زیبرت، سی. مرزبند، M. ویژگی های حرارتی و جنبه های ایمنی باتری های لیتیوم یونی: بررسی عمیق. تقارن ۲۰۲۳، ۱۵، ۱۹۲۵٫ [Google Scholar] [CrossRef]
- چن، تی. جین، ی. Lv، H.; یانگ، آ. لیو، ام. چن، بی. زی، ی. Chen, Q. کاربردهای باتریهای لیتیوم یونی در سیستمهای ذخیرهسازی انرژی در مقیاس شبکه. ترانس. دانشگاه تیانجین ۲۰۲۰، ۲۶، ۲۰۸-۲۱۷٫ [Google Scholar] [CrossRef]
- چن، جی سی. چن، T.-L. لیو، W.-J. چنگ، سی. لی، ام.-جی. ترکیب تجزیه حالت تجربی و شبکه های عصبی عود کننده عمیق برای نگهداری پیش بینی باتری لیتیوم یون Adv. مهندس آگاه کردن. ۲۰۲۱، ۵۰، ۱۰۱۴۰۵٫ [Google Scholar] [CrossRef]
- لیپو، MSH؛ میاه، س. جمال، ت. رحمان، ت. انصاری، س. رحمان، س. Ashique، RH; شیهاوالدین، ASM; Shakib، MN رویکردهای هوش مصنوعی برای سیستم مدیریت باتری پیشرفته در کاربردهای خودروهای الکتریکی: تحلیلی آماری به سمت فرصتهای تحقیقاتی آینده. وسايل نقليه ۲۰۲۴، ۶، ۲۲-۷۰٫ [Google Scholar] [CrossRef]
- او، س. یو، بی. لی، ز. ژائو، ی. تئوری تابعی چگالی برای مواد باتری. محیط انرژی ماتر ۲۰۱۹، ۲، ۲۶۴-۲۷۹٫ [Google Scholar] [CrossRef]
- ژانگ، سی. چنگ، جی. چن، ی. چان، MKY; کای، س. کاروالیو، آر.پی. مارچیوری، CFN؛ برندل، دی. آرائوجو، سی ام. چن، ام. و همکاران نقشه راه ۲۰۲۳ در مدل سازی مولکولی مواد انرژی الکتروشیمیایی. J. Phys. انرژی ۲۰۲۳، ۵۰۴۱۵۰۱٫ [Google Scholar] [CrossRef]
- ماچلو، آر. هیسترن، ال. پرل، ام. لوی، ک. بلیکوف، جی. مانور، اس. لورون، ی. تکنیکهای هوش مصنوعی قابل توضیح (XAI) برای سیستمهای انرژی و قدرت: بررسی، چالشها و فرصتها. هوش مصنوعی انرژی ۲۰۲۲، ۹، ۱۰۰۱۶۹٫ [Google Scholar] [CrossRef]
- عالم، مگاوات؛ باقیس، ع. رحمان، م.م. عامر، م. ابوذر، ع. مشتاق، س. امین، م.ن. خان، بررسی MS در مورد ZnFe با پوشش کربن در محل۲O4 به عنوان ماده آند پیشرفته برای باتری های لیتیوم یونی. ژل ۲۰۲۲، ۸، ۳۰۵٫ [Google Scholar] [CrossRef] [PubMed]
- جایاچیترا، جی. جاشوا، جی آر؛ بالاموروگان، ا. سیواکومار، ن. شارمیلا، وی. شانواس، س. ابوحیجه، م. عالم، مگاوات؛ BaQais، A. عملکرد الکترود بالا O3-NaFeO با پوشش C فعال شده توسط هیدروترمال توسعه یافته است.۲ الکترود برای کاربردهای باتری Na-ion سرام. بین المللی ۲۰۲۳، ۴۹، ۴۸-۵۶٫ [Google Scholar] [CrossRef]
- دیائو، دبلیو. ساکسنا، اس. Pecht, M. تست چرخه تسریع شده و مدلسازی کاهش ظرفیت LiCoO2-سلول های گرافیتی J. منابع قدرت ۲۰۱۹، ۴۳۵، ۲۲۶۸۳۰٫ [Google Scholar] [CrossRef]
- بنتژاک، سی. Csörgő، A. Martínez-Muñoz، G. تحلیل مقایسه ای الگوریتم های تقویت گرادیان. هنرها هوشمندانه. کشیش ۲۰۲۱، ۵۴، ۱۹۳۷-۱۹۶۷٫ [Google Scholar] [CrossRef]
- کای، بی. لی، ام. یانگ، اچ. وانگ، سی. Chen, Y. برآورد وضعیت شارژ باتری لیتیوم یون بر اساس شبکه عصبی پس انتشار و الگوریتم AdaBoost. انرژی ها ۲۰۲۳، ۱۶، ۷۸۲۴٫ [Google Scholar] [CrossRef]
- چن، تی. او، تی. Benesty، M. XGBoost: افراطی افزایش گرادیان. بسته R نسخه ۰٫۴-۲٫ ۲۰۱۵٫ در دسترس آنلاین: https://rdocumentation.org/packages/xgboost/versions/0.4-2 (دسترسی در ۱۲ مه ۲۰۲۴).
- Al Daoud, E. مقایسه بین XGBoost، LightGBM و CatBoost با استفاده از مجموعه داده اعتبار خانگی. بین المللی جی. کامپیوتر. Inf. مهندس ۲۰۱۹، ۱۳، ۶-۱۰٫ [Google Scholar]
- نوردین، ن. زینول، ز. نور، MHM; چان، LF یک مدل پیشبینیکننده قابل توضیح برای خطر اقدام به خودکشی با استفاده از رویکرد یادگیری گروهی و توضیحهای افزودنی Shapley (SHAP). روانپزشکی J. آسیایی ۲۰۲۳، ۷۹، ۱۰۳۳۱۶٫ [Google Scholar] [CrossRef] [PubMed]
- دی میتنایر، ا. گلدن، بی. لو گراند، بی. Rossi, F. میانگین درصد خطای مطلق برای مدل های رگرسیون. کامپیوترهای عصبی ۲۰۱۶، ۱۹۲، ۳۸-۴۸٫ [Google Scholar] [CrossRef]
- یین، جی. مدلهای یادگیری گروه Li، N. با الگوریتم بهینهسازی بیزی برای نگاشت آینده نگری مواد معدنی. سنگ معدن. کشیش ۲۰۲۲، ۱۴۵، ۱۰۴۹۱۶٫ [Google Scholar] [CrossRef]
- حسن، آر. احیای شبکه الکتریکی: الگوی یادگیری ماشین برای تضمین ثبات در ایالات متحده جی. کامپیوتر. علمی تکنولوژی گل میخ. ۲۰۲۴، ۶، ۱۴۱-۱۵۴٫ [Google Scholar] [CrossRef]
- Phyo، PP; بیون، YC; پارک، N. پیش بینی انرژی کوتاه مدت با استفاده از رگرسیون رأی گیری گروهی مبتنی بر یادگیری ماشینی. تقارن ۲۰۲۲، ۱۴، ۱۶۰٫ [Google Scholar] [CrossRef]
- آلدریس، آ. خان، م. طاها، ATB; علی، م. ارزیابی شاخصهای کیفیت آب با رویکردهای جدید یادگیری ماشین و توضیح افزودنی SHapley (SHAP). J. فرآیند آب. مهندس ۲۰۲۴، ۵۸، ۱۰۴۷۸۹٫ [Google Scholar] [CrossRef]
- Ma، K. مدلسازی ترکیبی یکپارچه و SHAP (توضیحات افزودنی SHapley) برای پیش بینی و توضیح خواص جذب مواد متخلخل پلی اورتان گرمانرم (TPU). RSC Adv. 2024، ۱۴، ۱۰۳۴۸–۱۰۳۵۷٫ [Google Scholar] [CrossRef] [PubMed]
- محمد، ع. کورا، آر. مروری جامع بر یادگیری عمیق گروهی: فرصتها و چالشها. J. King Saud Univ.-Comput. Inf. علمی ۲۰۲۳، ۳۵، ۷۵۷-۷۷۴٫ [Google Scholar] [CrossRef]
- چاندران، وی. پاتیل، CK; کارتیک، ا. گانشاپرومال، دی. رحیم، ر. Ghosh, A. برآورد وضعیت شارژ باتری لیتیوم یونی برای وسایل نقلیه الکتریکی با استفاده از الگوریتم های یادگیری ماشین. ورلد الکتر. وه جی. ۲۰۲۱، ۱۲، ۳۸٫ [Google Scholar] [CrossRef]
- دینوا، ا. Kocsis، SS; Vajda، I. پیش بینی ولتاژ ترمینال مبتنی بر داده باتری های لیتیوم یون تحت بارهای دینامیکی. در مجموعه مقالات بیست و یکمین سمپوزیوم بینالمللی ۲۰۲۰ در دستگاهها و فناوریهای الکتریکی (SIELA)، بورگاس، بلغارستان، ۳ تا ۶ ژوئن ۲۰۲۰؛ صص ۱-۵٫ [Google Scholar] [CrossRef]
- پوه، WQT؛ خو، ی. Tan, RTP مروری بر کاربردهای یادگیری ماشین برای تخمین وضعیت باتری لیتیوم یونی در وسایل نقلیه الکتریکی. در مجموعه مقالات فناوریهای شبکه هوشمند نوآورانه IEEE PES 2022-Asia (ISGT Asia)، سنگاپور، ۱ تا ۵ نوامبر ۲۰۲۲٫ [Google Scholar] [CrossRef]
- آستانه، م. آندریک، جی. لوفدال، ال. ماگیلو، دی. استاپ، پی. مقدم، م. چاپویس، م. Ström، H. روش بهینهسازی کالیبراسیون برای مدل بسته باتری لیتیوم یونی برای وسایل نقلیه الکتریکی در کاربردهای معدن. انرژی ها ۲۰۲۰، ۱۳، ۳۵۳۲٫ [Google Scholar] [CrossRef]
- Chehade, AA; حسین، AA یک مدل فرآیند گاوسی پیچیده چند خروجی برای تخمین ظرفیت سلولهای باتری لیتیوم یون خودروی الکتریکی. در مجموعه مقالات کنفرانس و نمایشگاه برق رسانی حمل و نقل IEEE 2019 (ITEC)، دیترویت، MI، ایالات متحده آمریکا، ۱۹ تا ۲۱ ژوئن ۲۰۱۹٫ [Google Scholar]
- دو، آر. هو، ایکس. زی، اس. هو، ال. ژانگ، ز. Lin, X. مدیریت انرژی پیشبینیکننده دما و پیری باتری برای خودروهای الکتریکی هیبریدی. J. منابع قدرت ۲۰۲۰، ۴۷۳، ۲۲۸۵۶۸٫ [Google Scholar] [CrossRef]
شکل ۱٫
فلوچارت مدل ها.
شکل ۱٫
فلوچارت مدل ها.
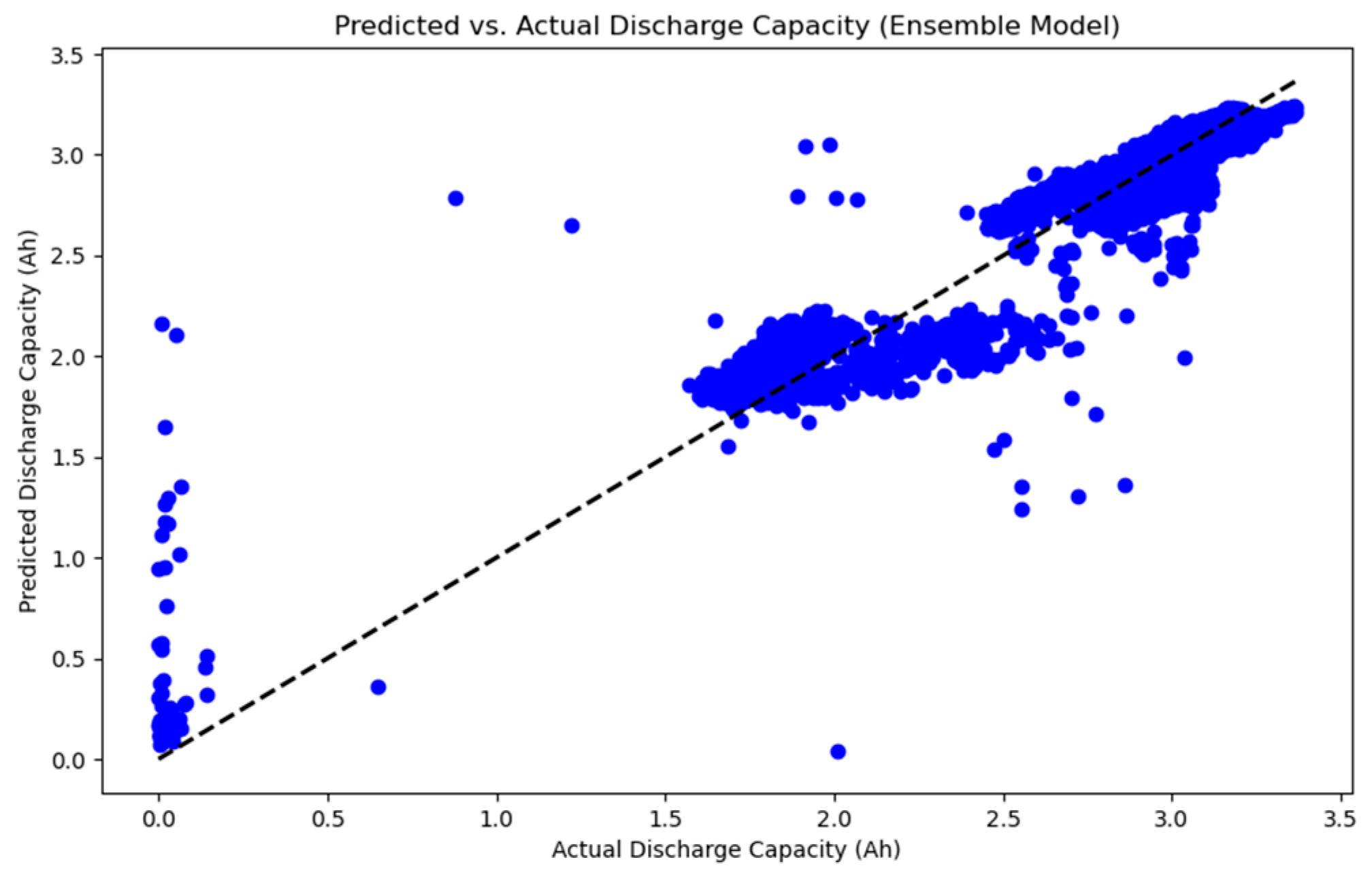
شکل ۲٫
پیشبینیشده در مقابل مقادیر واقعی مدلها.
شکل ۲٫
پیشبینیشده در مقابل مقادیر واقعی مدلها.
شکل ۳٫
مدل واقعی و پیش بینی شده مجموعه
شکل ۳٫
مدل واقعی و پیش بینی شده مجموعه
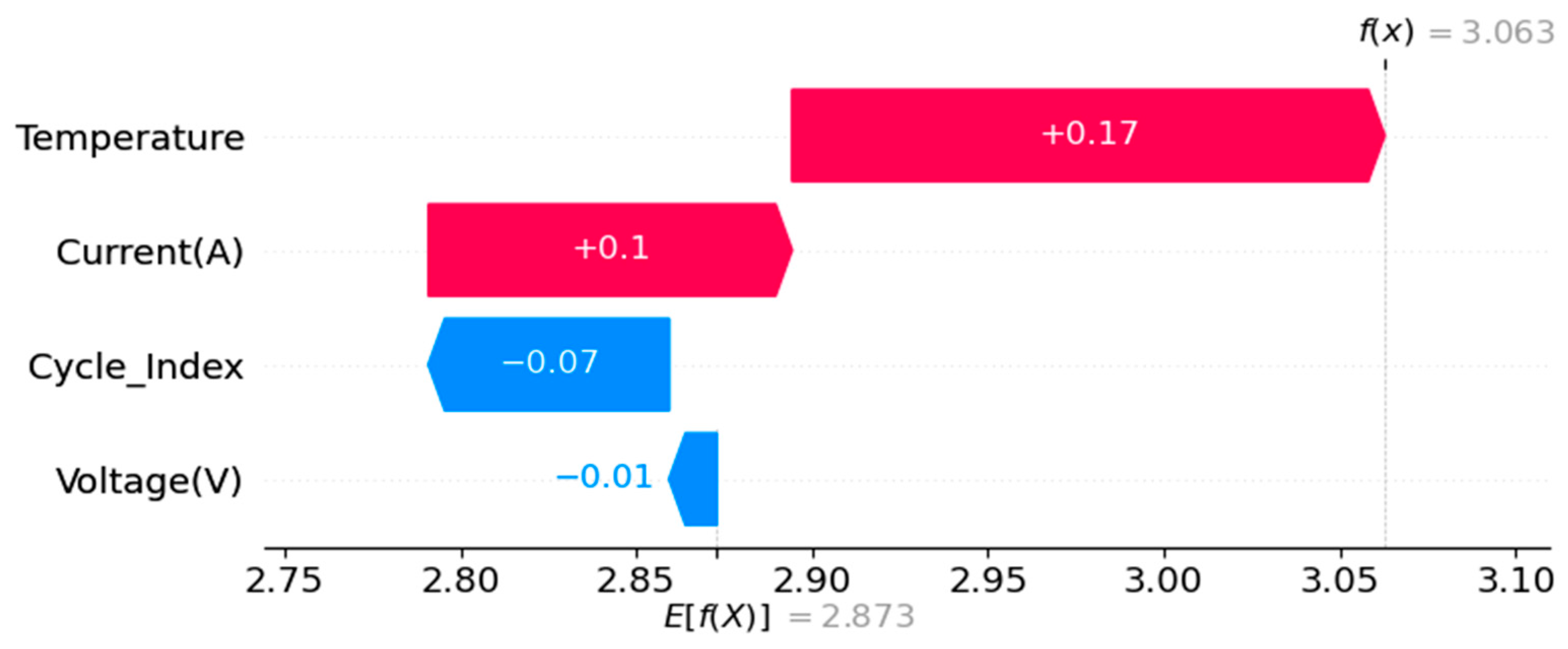
شکل ۴٫
آبشار ارزش SHAP برای مدل LGBM.
شکل ۴٫
آبشار ارزش SHAP برای مدل LGBM.
شکل ۵٫
قابلیت توضیح پارامترهای مدل LightGBM با مقادیر مدل SHAP.
شکل ۵٫
قابلیت توضیح پارامترهای مدل LightGBM با مقادیر مدل SHAP.
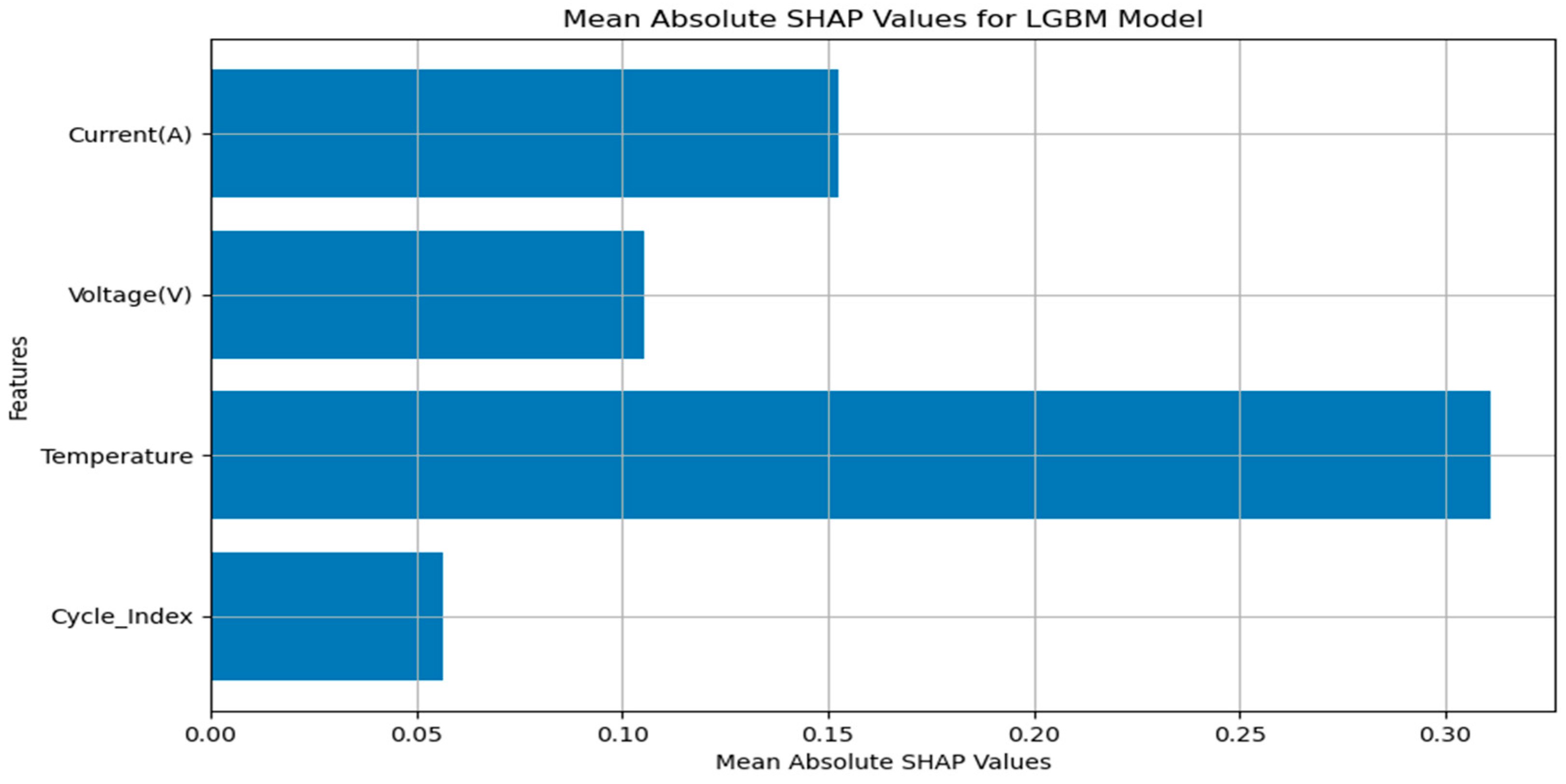
شکل ۶٫
میانگین مقادیر مطلق SHAP برای مدل LightGBM.
شکل ۶٫
میانگین مقادیر مطلق SHAP برای مدل LightGBM.
روش های آزمایشی که روی سلول ها اعمال می شود [۱۸].
روش های آزمایشی که روی سلول ها اعمال می شود [۱۸].
| تخلیه C-Rate | دمای محیط (°C) | دشارژ C-Rate C | |||
|---|---|---|---|---|---|
| ۱۰ | ۲۵ | ۴۵ | ۶۰ | ||
| ۰٫۷ C | تست شماره ۱ | تست شماره ۷ | تست شماره ۱۳ | تست شماره ۱۹ | ج/۵ |
| تست شماره ۲ | تست شماره ۸ | تست شماره ۱۴ | تست شماره ۲۰ | C/40 | |
| ۱ C | تست شماره ۳ | تست شماره ۹ | تست شماره ۱۵ | تست شماره ۲۱ | ج/۵ |
| تست شماره ۴ | تست شماره ۱۰ | تست شماره ۱۶ | تست شماره ۲۲ | C/40 | |
| ۲ C | تست شماره ۵ | تست شماره ۱۱ | تست شماره ۱۷ | تست شماره ۲۳ | ج/۵ |
| تست شماره ۶ | تست شماره ۱۲ | تست شماره ۱۸ | تست شماره ۲۴ | C/40 | |
جدول ۲٫
فراپارامترهای مدل ها
جدول ۲٫
فراپارامترهای مدل ها
| مدل ها | فراپارامترها |
|---|---|
| AdaBoost | n_estimators = 100 |
| نرخ_آموزش = ۰٫۲ | |
| ضرر = “خطی” | |
| افزایش گرادیان | n_estimators = 100 |
| نرخ_آموزش = ۰٫۱ | |
| حداکثر_عمق = ۳ | |
| min_samples_split = 2 | |
| min_samples_leaf = 1 | |
| XGBoost | n_estimators = 100 |
| نرخ_آموزش = ۰٫۱ | |
| حداکثر_عمق = ۳ | |
| نمونه فرعی = ۰٫۸ | |
| colsample_bytree = 0.8 | |
| گاما = ۰ | |
| حداقل_وزن_کودک = ۱ | |
| LightGBM | n_estimators = 100 |
| حالت_تصادفی = ۴۲ | |
| CatBoost | n_estimators = 100 |
| حالت_تصادفی = ۴۲ | |
| پرمخاطب = ۰ |
جدول ۳٫
نتایج مقایسه مدل
جدول ۳٫
نتایج مقایسه مدل
| مدل ها | MAE | MSE | R-Squared |
|---|---|---|---|
| AdaBoost | ۰٫۱۳۴ | ۰٫۰۴۱ | ۰٫۷۶۳ |
| افزایش گرادیان | ۰٫۱۰۸ | ۰٫۰۲۳ | ۰٫۸۶۴ |
| XGBoost | ۰٫۱۱۰ | ۰٫۰۲۳ | ۰٫۸۶۴ |
| LightGBM | ۰٫۱۰۳ | ۰٫۰۱۹ | ۰٫۸۸۷ |
| CatBoost | ۰٫۱۰۴ | ۰٫۰۲۰ | ۰٫۸۸۱ |
|
سلب مسئولیت/یادداشت ناشر: اظهارات، نظرات و داده های موجود در همه نشریات صرفاً متعلق به نویسنده (ها) و مشارکت کننده (ها) است و نه MDPI و/یا ویرایشگر(ها). MDPI و/یا ویرایشگر(های) مسئولیت هرگونه آسیب به افراد یا دارایی ناشی از هر ایده، روش، دستورالعمل یا محصولی را که در محتوا ذکر شده است، سلب میکنند. |
منبع:
۱- shahrsaz.ir , پایداری | متن کامل رایگان | بهینه سازی عملکرد باتری لیتیوم یون: ادغام یادگیری ماشین و هوش مصنوعی قابل توضیح برای مدیریت انرژی پیشرفته
,۲۰۲۴-۰۶-۰۳ ۰۳:۳۰:۰۰
۲- https://www.mdpi.com/2071-1050/16/11/4755
ادغام , انرژی , باتری , برای , بهینه , پایداری , پیشرفته , توضیح , رایگان , سازی , عملکرد , قابل , کامل , لیتیوم , ماشین , متن , مدیریت , مصنوعی , هوش , یادگیری , یون
- دیدگاه های ارسال شده توسط شما، پس از تایید توسط تیم مدیریت در وب منتشر خواهد شد.
- پیام هایی که حاوی تهمت یا افترا باشد منتشر نخواهد شد.
- پیام هایی که به غیر از زبان فارسی یا غیر مرتبط باشد منتشر نخواهد شد.